- Data Professor
- Posts
- Data Science Starter Kit
Data Science Starter Kit
A guide for getting started in data science
Chanin Nantasenamat
June 01, 2021
This article presents you the Data Science Starter Kit that will serve as a self-help guide to help you get started in your data science journey. Nope, I’m not selling you a course. Nor is it going to be a magical formula that will effortlessly instill you with data science knowledge and skills.
This Data Science Starter Kit is going to cost you ZERO dollars (although the learning service providers mentioned herein does). What this starter kit can do for you is provide a framework that will help pinpoint you in the right direction and help you take your first steps.
It’s going to be tough journey. You might even want to give up, but with perseverance and the right mindset you can do this. There’s a lot to cover here and without further ado, let’s get started!
Importance of Data Science
Data science can be defined as a multidisciplinary field for drawing actionable insights from data. It does this by applying the scientific method along with essential technical and analytical skills encompassing mathematics, statistics, programming, machine learning and data visualization.
The popularity of data science can be attributed to the catchy tag line from the article by Thomas Davenport and DJ Patil published an article in the Harvard Business Review:
Data Scientist: The Sexiest Job of the 21st Century
Nearly all Fortune 500 companies hire data scientists, data engineers and data analysts as well as machine learning researchers and machine learning engineers to help the orgnization make the most use of data.
You are aware that “data is the new oil” and that it can also help you make data-driven decisions. But the question is, how do you exactly get started and take the first steps in learning how to do data science.
Mindset
Sometimes we are overwhelmed with the possibilities and this leads to indecisiveness. Such situation is known as analysis paralysis. Consider the following common scenarios that we may all face when starting out.
Which course should we take?
Google Data Analytics or IBM Data Science certificate from Coursera.Which language to learn?
R vs PythonWhich data visualization tool?
Tableau or Power BI
Such overthinking may hinder productivity and keep us from moving forward. The reason why we are reluctant to just choose one and move on stems from our fear of making the wrong decision or going with a sub-optimal solution.

Photo by Daniel Öberg on Unsplash
A popular Chinese proverb once said:
“The best time to plant a tree was 20 years ago. The second best time is now.”
Thus, to move forward in your journey of learning data science, you will have to act and you will have to act now. Time is of the essence. So the answer to the above questions would be to choose one, give it a try and if it doesn’t work out then you can always switch and try the other one. Nothing is stopping you from trying out all the choices.
Data Science Skill Sets
A fundamental question in any learning journey is to figure out which courses you want to learn about. To help get you started, I’ve compiled a list of essential data science skill sets and boiled them down to an infographic shown below.
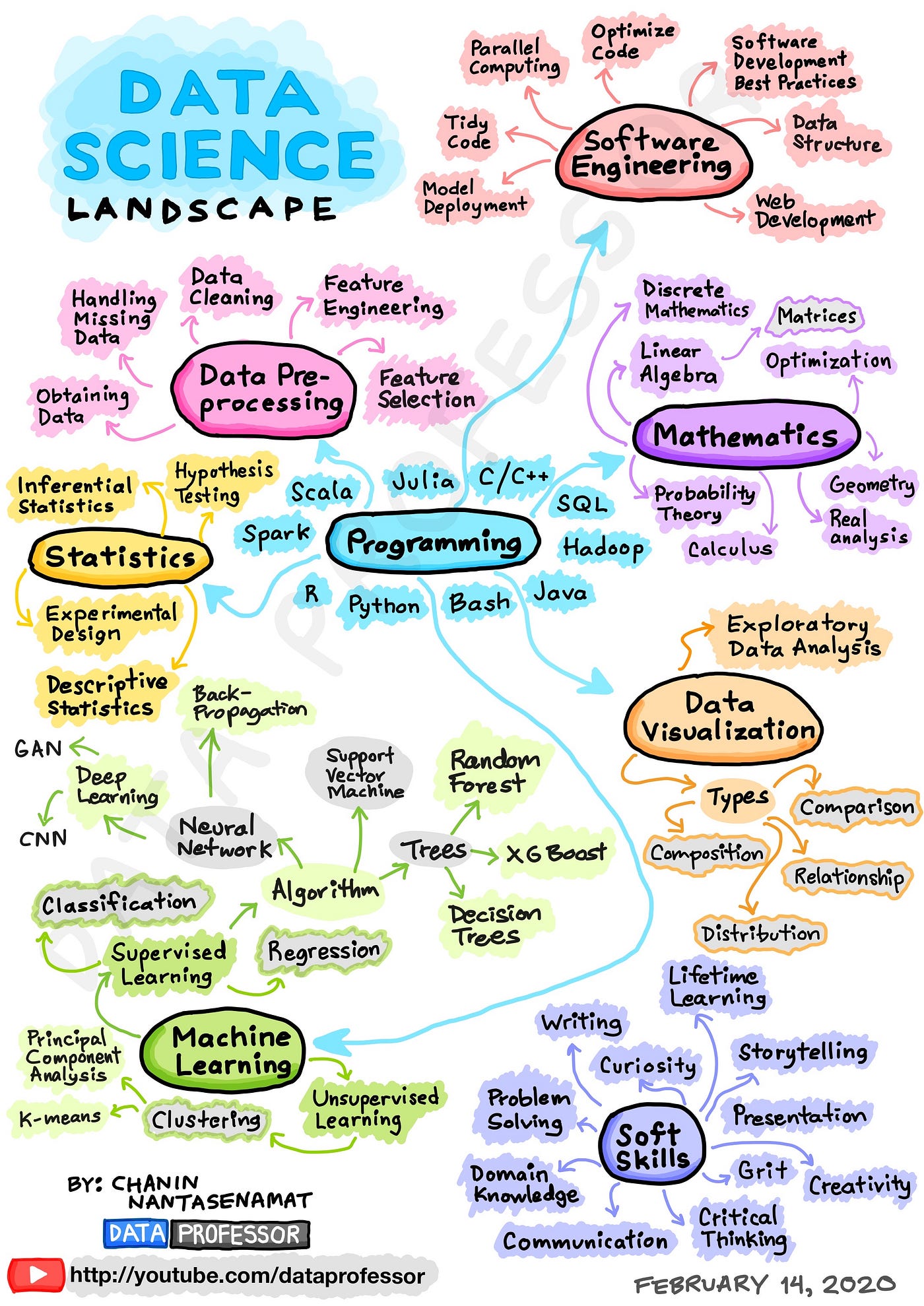
Infographic drawn by the Author.
At a high-level, the essential skill sets of a data scientist is depicted in the infographic shown below. This is essentially comprised of technical skills and soft skills for a well-rounded data scientist.
Technical skill sets of data science involves the use of:
Data collection,
Data pre-processing,
Exploratory data analysis,
Data visualization,
Statistical analysis,
Machine learning,
Programming and
Software engineering.
A more extended discussion of the data science skill sets is provided in a YouTube video I made on How to Become a Data Scientist (Learning Path and Skill Sets Needed).
The exact skill sets that any individual data scientist will actually do in their job is highly dependent on the type of company that they are working at.
For example, at a tech startup, data scientists may be expected to or are demanded by their role to cover a broad spectrum of skill sets covered in the infographic. So to say, they may eventually grow to become a full-stack data scientist. Personally, I started out as a biologist end-user of machine learning softwares such as the GUI-based WEKA data mining tool. Over time I began to acquire additional skill sets covered in the infographic such as coding (Python and R) as well as slowly embracing each of the skill set clusters. As for those working at a bigger tech company, the spectrum of their responsibilities may be narrower and more well-defined . For instance, data scientists at the big tech may specialize in developing novel machine learning algorithms, tools or frameworks.
Equally important are the various soft skills that help data scientists to tell good data stories, problem solve, devise creative solutions, etc. Rebecca Vickery wrote a great article covering this topic of Soft Skills for Data Science where she covers skepticism, persverance, creativity, business acumen and communication. These soft skills are ever more important as a data scientist moves up the career ladder as they are convey data-driven insights to key stakeholders of the organization as well as using these soft skills to manage a growing team of data professionals.
Learning Resources for Data Science
Coming from a non-technical background, I know how intimidating it may be to get started in data science. It’s not that there are few resources for learning data science, on the contrary, there is simply too much resources out there. As discussed previously, this may lead to analysis paralysis.
Here are some of the available resources for learning data science:
Bootcamps — Data Science Dojo, Lambda School
Conferences — DATAcated Conference, Open Data Science Conference
Workshops — NVIDIA Data Science Workshops, UC Berkeley’s National Workshop on Data Science Education
Competitions — Kaggle
Undergraduate or Graduate degree programs — UT Dallas, U Penn MCIT, etc.
Online Courses and Certificates — 365 Data Science, DataCamp, Coursera, DataQuest, Udemy, Udacity or Skillshare as well as the free Kaggle Learn
Books — Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, R for Data Science, Build a Career in Data Science, etc.
YouTube — Data Professor, Ken Jee, Krish Naik, codebasics, Daniel Bourke, Tina Huang, StatQuest, DATAcated, etc.
Medium — Chanin Nantasenamat, Ken Jee, Khuyen Tran, Richmond Alake, SeattleDataGuy, Rebecca Vickery, Terence Shin, etc.
Podcasts — Ken’s Nearest Neighbors, Chai Time Data Science, Towards Data Science, The Ravit Show
Social platforms — Follow hashtags #66daysofdata on Twitter, #100daysofcode on Twitter, #66daysofdata on LinkedIn and #100daysofcode on LinkedIn
As you can see these learning resources provide a wide range of options that you can leverage to learn data science. Each of the above resources are viable approaches and needless to say they may be suited for different life’s situations and circumstances that may vary from one individual to the next.
For example, if you’re in a rush to land a data science job as soon as possible and you have the time and financial means to support yourself through a bootcamp then this may be the route for you.
Or perhaps, you’re supported by your company to learn data science and you have the means to attend workshop or seminars then this may be a viable path for you.
For those who wants to transition from an entirely different field, you may be self-studying and therefore online resources that allows you to study from home may be your path.
Or if you know early on that you love data science and you have enrolled in an undergraduate degree program in data science, that’s also perfectly fine!
Based on my own personal experience, I often find it helpful to work on a project that interests me. For one, if the topic is interesting, the quest to make sense of the data by working on the project would be fun and engaging. In fact, I look forward to that time of the day when I get to learn or work on projects. I work a 9-to-5 job as an Associate Professor of Bioinformatics and in the evening I would get to work on content creation either coding for a tutorial, filming a tutorial video or writing a tutorial blog for Medium. Who knows, maybe one day I’ll be able to entirely devote my full time to content creation.
Hardware
An important component of any data science project is the hardware. Let’s get acquainted with some of the hardware that is instrumental for any data science project.
As computers (either laptop or desktop form) are important for performing various resource-intensive machine learning (or deep learning) model building, thus there may be a misconception that if we don’t have access to expensive hardware, it may be difficult to get started in data science. Although the lack thereof may seemingly hinder the progress of a data science project, but the availability of free cloud resources is a game changer.
If, however, there is a budget and you’re asking me what is my recommendation, I would recommend that you get a hold of a MacBook Pro, which I think is by far the best laptop available on the market for any coding related task as well as general productivity and content creation tasks. As the operating system of a MacBook is the OSX, it is essentially built on top of a BSD UNIX which shares similarities with Linux. The benefit of this is that you’ll become familiar with Linux commands as getting some machine learning software or tools installed on the computer may require some hacking into Apple’s Xcode and Homebrew. Another benefit is that the laptop could double as a desktop if connected to an external monitor, keyboard and mouse.
Google Colab and Kaggle Notebook are free and yet powerful cloud resources that confers any user access to CPU and GPU computing resources. Armed with only a basic laptop, you too can have access to powerful computing resources that will be sufficient to train just about any model.
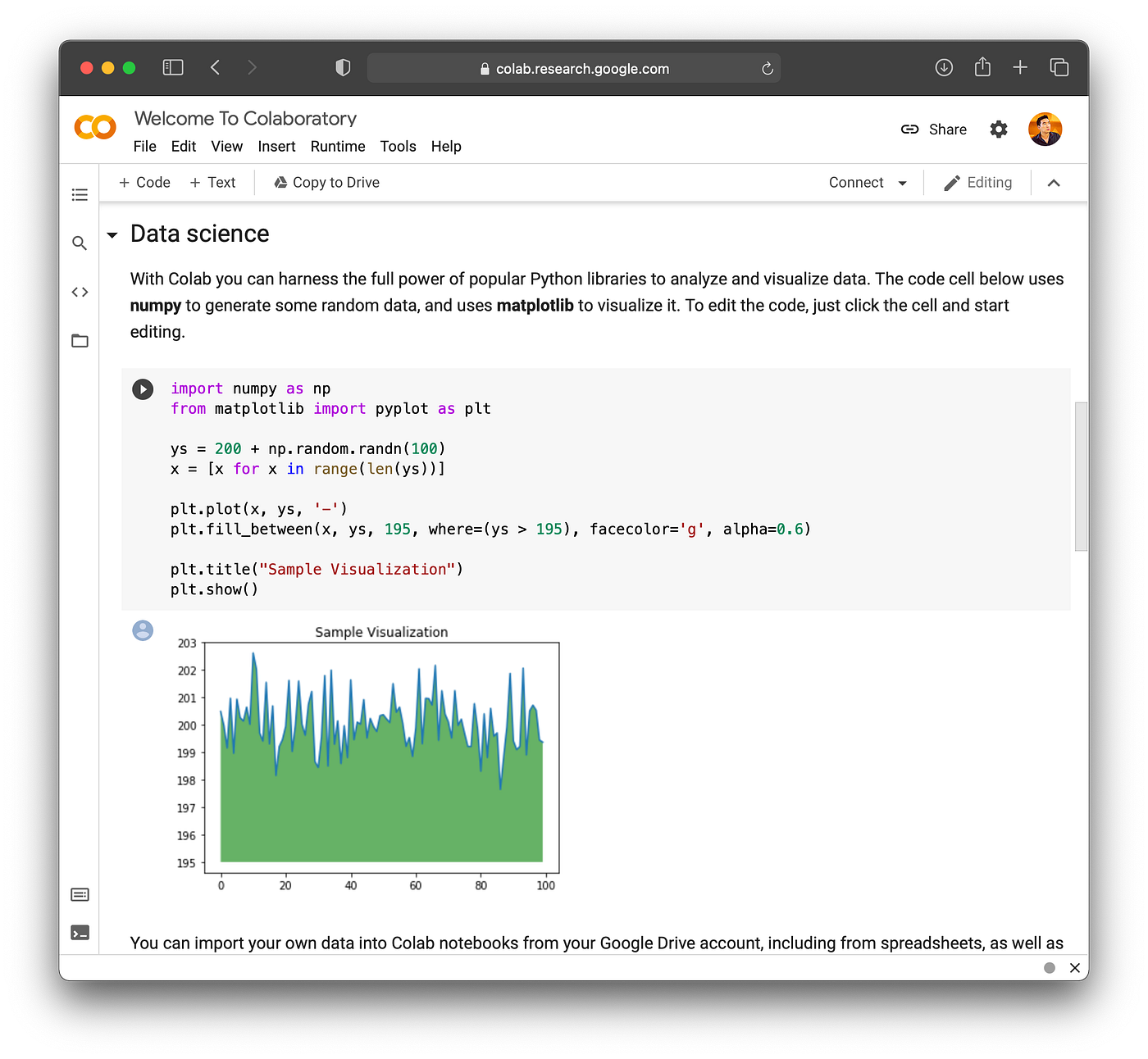
Screenshot of Google Colab notebook.
It should however be noted that for Google Colab, access to higher-end GPU computing resources is not always guaranteed as it is shared amongst the vast user base, however with persistence. Particularly, a simple refresh of the browser a couple of times, you may gain access to the higher tier NVIDIA T4 GPU card as opposed to the older NVIDIA K80 GPU card.
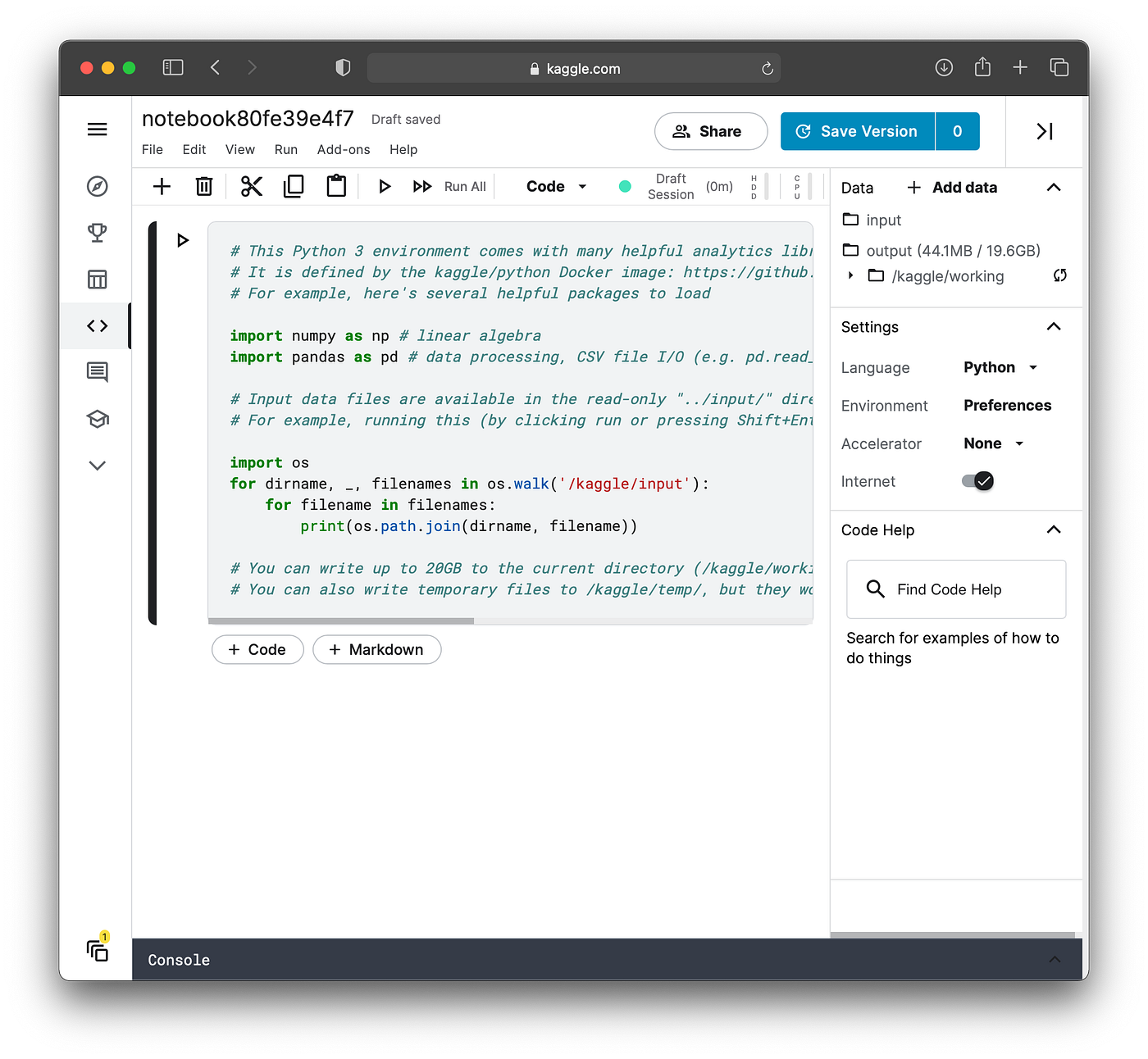
Screenshot of Kaggle Notebook.
As for Kaggle Notebook, there’s a 30 hour per week limit for using GPU. A great think about Kaggle Notebook is its native support for both Python and R while Google Colab only supports Python at the moment while a hack to temporarily support R or even Julia is also possible. A difference that sets Google Colab and Kaggle Notebook apart is the in built community associated with Kaggle. Particularly, the notebook on Kaggle could also be upvoted if they’re useful or provide value to the community.
Aside from this cloud virtual private servers also provide additional venues that we can harness to gain access to large computing power in a matter of minutes or seconds. Some of these cloud service providers include:
Software
A good hardware without the proper software would not be of benefit to you. There are a wide range of software and tools that can improve your productivity. Let’s take a look at these.
Planning your Study Plan
Being organized and having a well-structured plan can help you eliminate time that could otherwise be put into better use. For example, if you have a clear study or work schedule that you can refer to when learning data science or working on data science projects, you’re at an advantage as compared to figuring out on the fly what you want to learn or what project you want to work on today, tomorrow or the day after.
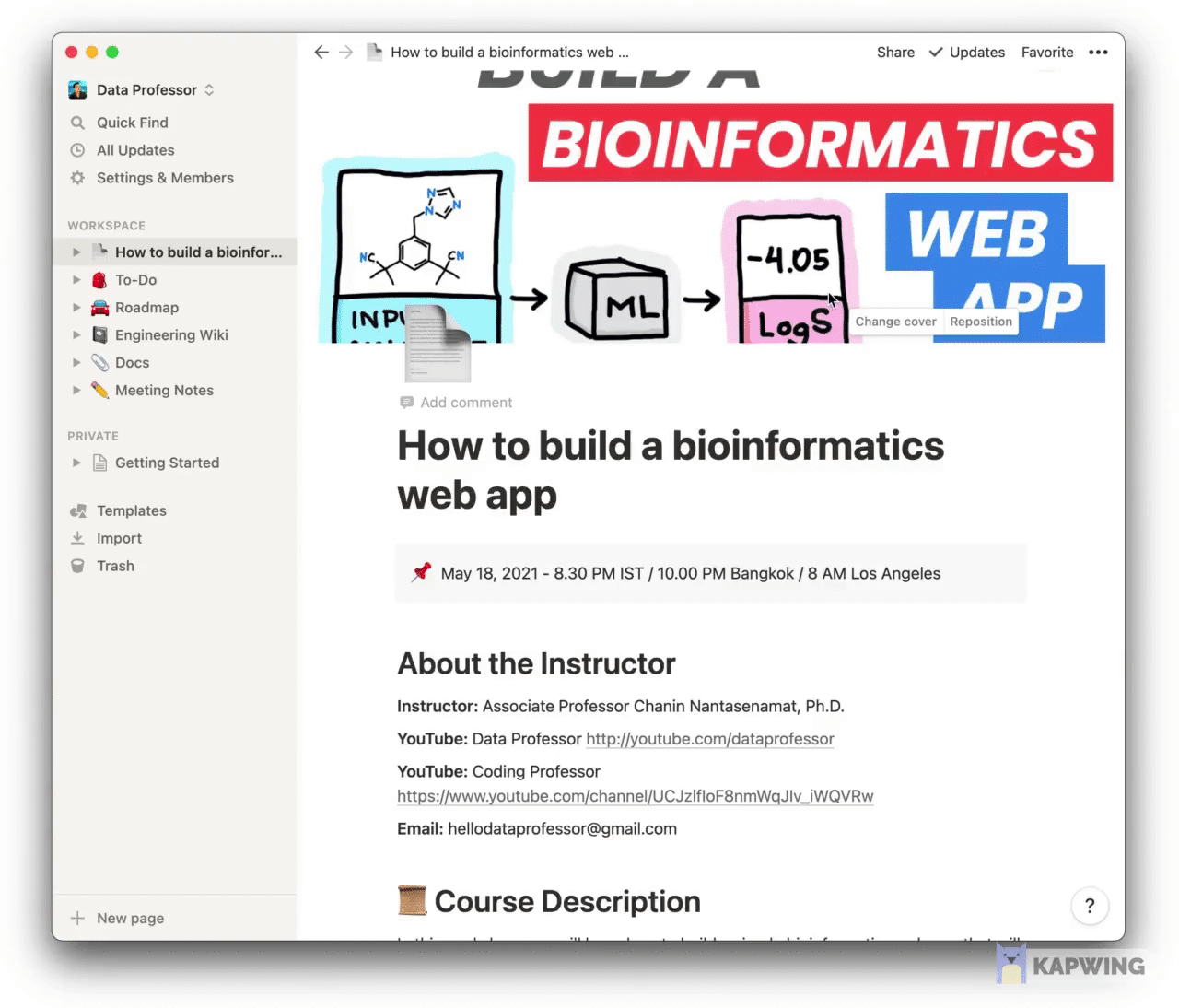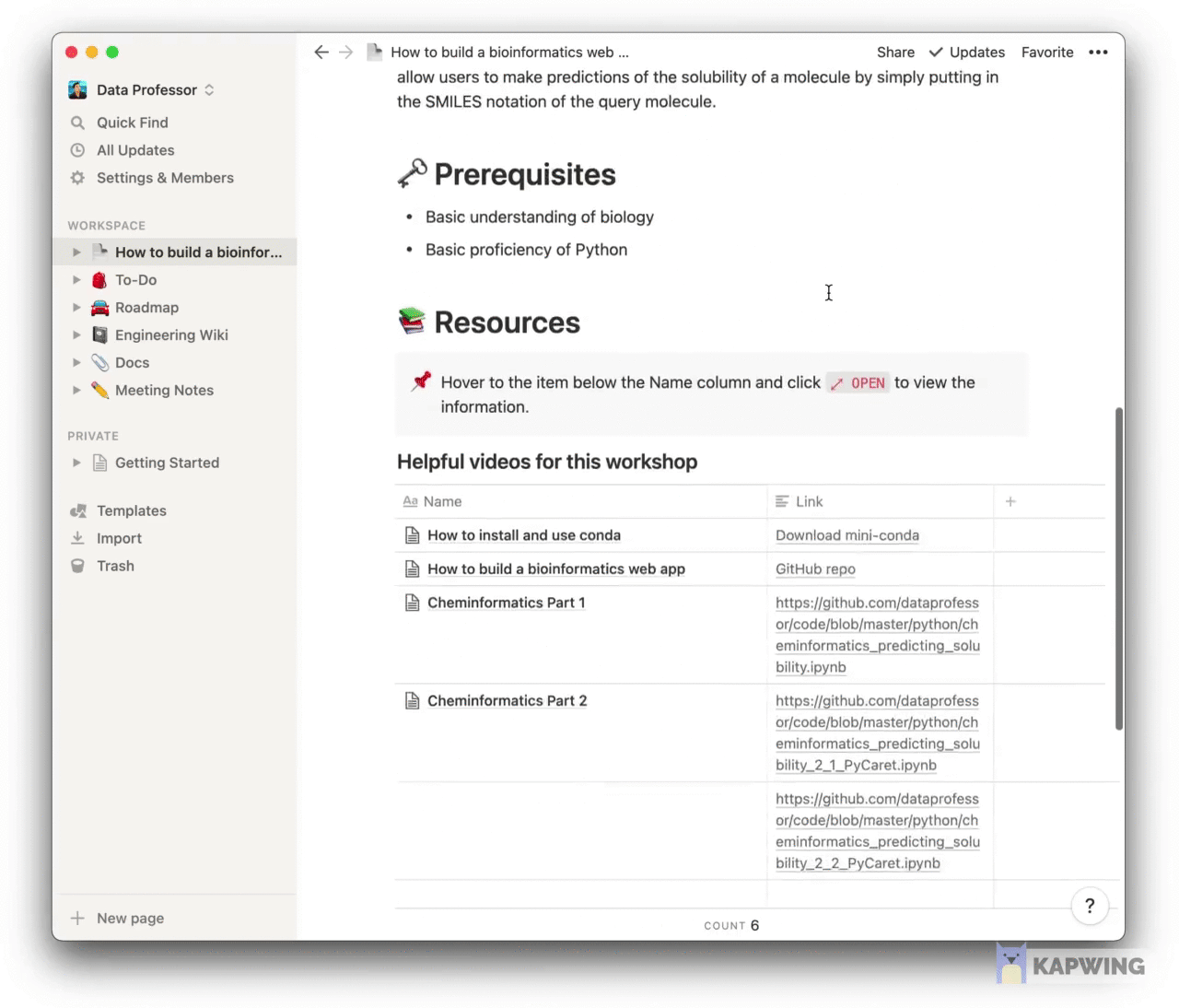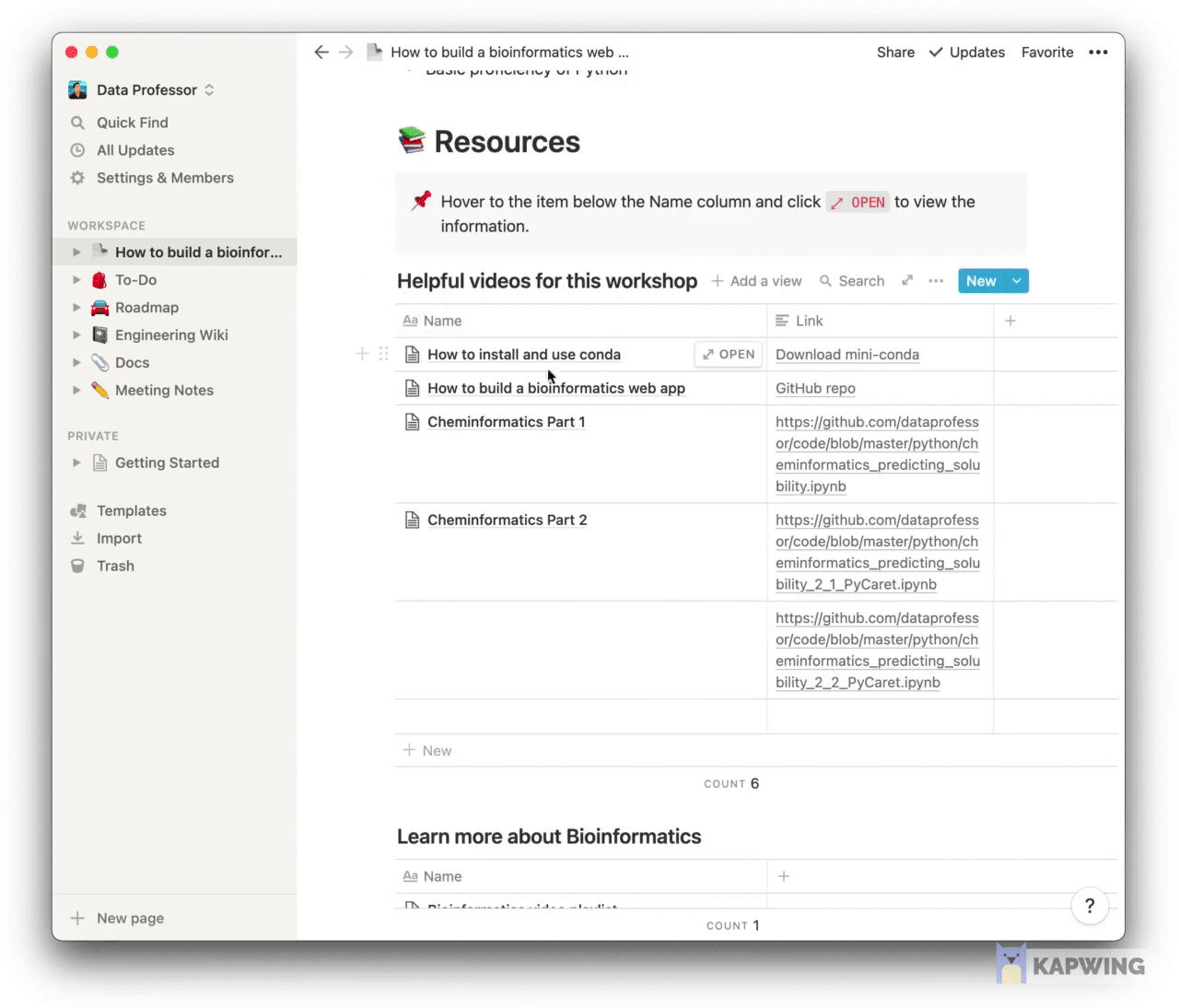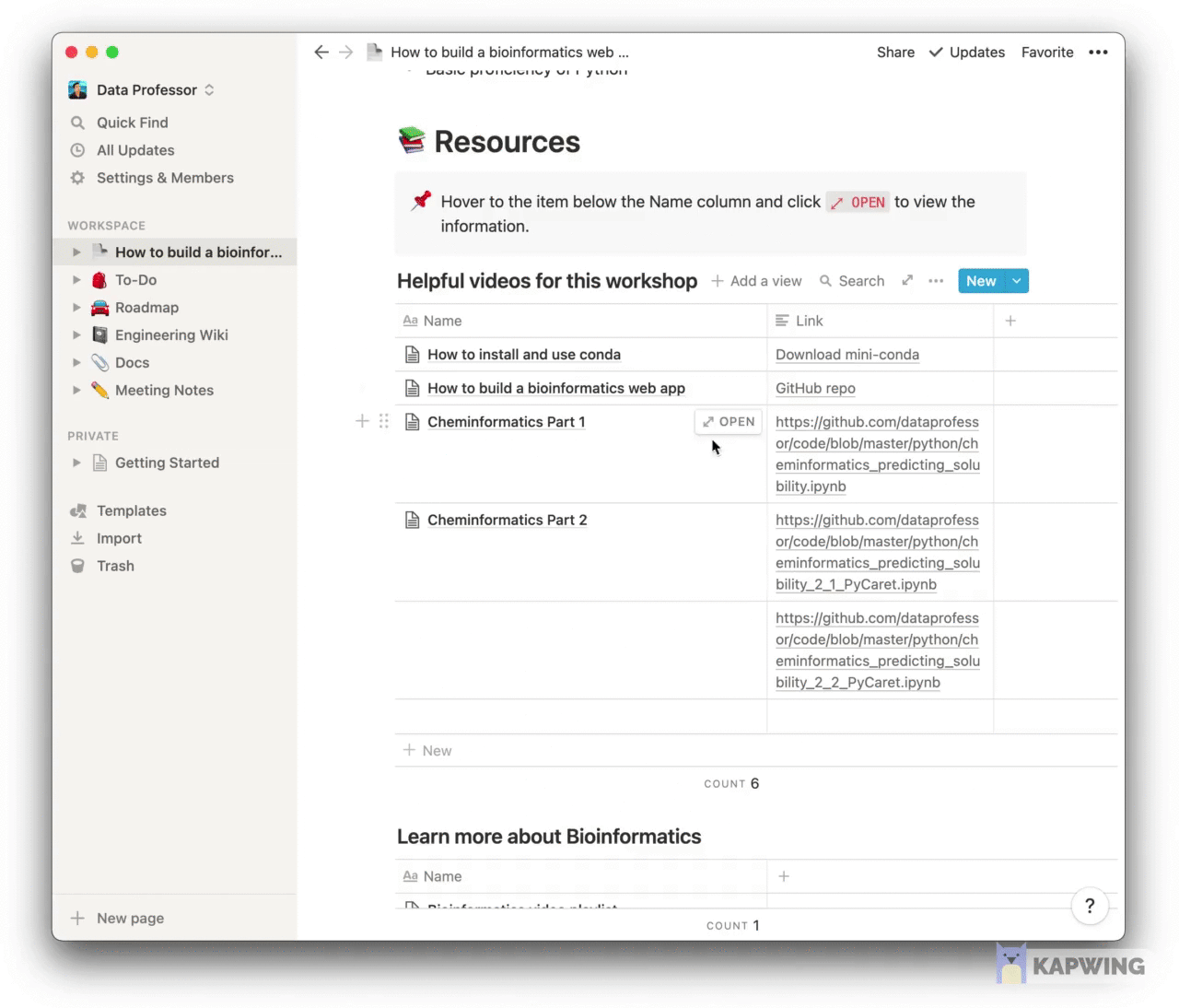
Screenshot of a syllabus for a bioinformatics workshop that I developed using Notion.
Arm yourself with a clear schedule and study plan, it can go a long way in keeping you in check and reinforcing your productivity. Imagine the situation when you are going grocery shopping without a shopping list. Although you may figure out on the fly what you need. Chances are by the time you got home, you might have found out that you may have forgot to purchase some important items. Thus, a shopping list that you jot down may help to prevent such scenarios from happening.
Likewise, in your data science learning journey, make a list of the topics that you want to learn about or go into more depth on. You can start by making a simple check list. A great tool that you can use is Notion, which I’ll soon make a video about on my YouTube channel Data Professor.
In a recent online tutorial that I taught at a Bioinformatics workshop, I used Notion to create a shareable syllabus of the session. A great thing about this is that the created syllabus can be shared as a webpage at the click of a button.
Integrated Development Environment (IDE)
The IDE is probably the backbone of any data science project as it can be thought of as the home to your data and code.
Screenshot of Notepad++ website showing the text editor.
An IDE can come in many shape and form where it can range from a simple text editor to a full-fledged IDE with bells and whistles. In addition, Jupyter notebooks and its variants could be thought of as another IDE in the middle of this spectrum.
Screenshot of Atom.io website showing the IDE.
A simple text editor such as Notepad++ and the base version of Atom is light weight and may get you through simple projects. It should be noted that Atom is customizable whereby additional packages and themes can upgrade your text editor to a full-fledged IDE.
A powerful IDE that a lot of developers are familiar with is Visual Studio Code or simply VS Code. Aside from syntax highlighting, it also has support for running the code in the integrated terminal, version control via Git, etc. It should be noted that Atom also has support for these features upon installation of additional packages.
Screenshot of VS Code website showing the IDE.
VS Code and Atom not only support Python but they equally handle other programming languages well such as C, C++, Java, Javascript, HTML, Julia, etc. Furthermore, both have cross-platform support and works on Windows, Linux and OSX.

Screenshot of the Spyder website showing its IDE.
A great feature of IDEs that I really like is the variable explorer function which has always been a core feature of Spyder that is reminiscent of the that of MATLAB. This is probably one of the handiest feature of an IDE, as the ability to view values of variables in the the variable explorer eliminates the need to constantly print out the values in the interactive command line.
Another feature that I also like is the plot window where we get to see a preview of the plot without having to first writing it to file. Nowadays, other IDEs also provide plug-ins to support these feature.
Screenshot of the PyCharm website showing its IDE.
As already mentioned for Atom, users of VS Code, Spyder and PyCharm allows you to customize the IDE further by installing additional plug-ins.
A notable plug-in that I find particularly useful is the free AI-powered code completion from Kite, which currently supports all the major IDEs.
Kite analyzes the context of the code and through AI it suggests the next course of action by suggesting possible lines of code that you are likely to type next. Saving a few seconds here and there could snowball over time.

Screenshot of the Kite website showing it in action for code completion. Notice the suggested code block as a drop-down as the code is being typed.
Consistency
In late 2020, good friend of mine and a prominent data science YouTuber Ken Jee, has started the 66 Days of Data initiative with the intention of instilling good learning habits for aspiring data scientists.
The #66daysofdata challenge is designed to help create great data science learning habits. In addition to the habits you will be joining a thriving community where you can learn alongside and work with other likeminded people.
Participating in the challenge is simple. There’s only 2 parts to it.
Learn data science every day for 66 days straight. You should learn for a minimum of 5 minutes per day.
Share your progress on your social media platform of choice using #66daysofdata tag.
This has 3 main benefits as Ken explains (read more about it):
You create a habit of daily learning which is integral to your success in the data science and machine learning career paths.
You get used to sharing your work, something that can help you to create many opportunities for yourself.
The community holds you accountable. This is often the missing piece for many people looking to learn these skills.
Work on Data Projects
Reading, watching and listening are passive learning, which are good for picking up new concepts but to truly internalize and materialize the newfound knowledge it is essential that you translate these into action. How so? By working on data projects.
What projects to work on?
Kaggle — Kaggle is a great way to explore what data challenges are available to work on. Additionally, you’ll also get the chance to take a glimpse of public notebooks created by fellow Kagglers for which to inspire your own implementation.
Personal data projects — Look around you to see what sparks your interest. For example, if you are a blogger on Medium, you can download your user data that you can analyze. In fact, eminent Medium write Zulie Rane wrote an article How to Analyze Your Medium Stats with R. Similarly, you could also analyze your Netflix viewing activity. For this, Saúl Buentello wrote Explore your activity on Netflix with R: How to analyze and visualize your viewing history. There’s so much data out there that may be of interest to you, because if it does you will be more likely to find it fun and engaging.
Data sources
Toy datasets — Several Python libraries include some form of toy datasets that you can experiment with when setting up your data projects.
— Scikit-learn
— TensorFlow
— SeabornGoogle Dataset Search — Is a search engine of datasets available on various repositories across the internet.
Data Repository @ Data Professor GitHub — I would occasionally add new datasets to this repo for you to use. Many of the datasets are from my tutorial videos such as a bioinformatics dataset that you can build yourself from scratch. If you’re interested in that, then check out the 6-Part Bioinformatics from Scratch series playlist.
As mentioned above, it is highly recommended that you share what you’ve learned to the data community of likeminded people so as to form a habit of daily learning as well as being accountable. In addition to a short post on Twitter or LinkedIn, you can also share what you’ve learned in the form of a blog post on Medium.
What better way to share your knowledge than to write about it (or even make a video about it and share it on YouTube). Writing a tutorial blog is a great way to solidify what you’ve learned as well as help others to learn as well.
Some key resources to get you started in writing your first blog is to consider the following videos/articles:
How to write technical blog posts
by Quincy Larson (Founder of freeCodecamp)Let’s Write a Data Science Blog Post From Scratch
by Akash (Co-founder and CEO of Jovian)Get Started Blogging on Medium: a 4 part walkthrough for beginners on Medium
by Zulie Rane (Medium Writer and YouTuber)
Build your Portfolio and Portfolio Website
A portfolio helps you to showcase your data science projects that may potentially appeal to potential employers as well as allowing you to archive your learned expertise in data science. The sharing of code and data of your data science projects may also be immensely beneficial to the data community especially to other aspiring data scientists. So where do you share the data and code to your projects? A recommended platform is GitHub, although there are similar alternatives such as BitBucket or GitLab.
GitHub repository for Building a Bioinformatics Web App in Python.
An example of a GitHub repository for a tutorial I made on my YouTube channel on Building a Bioinformatics Web App in Python is shown in the screenshot to the left.
As you can see, all code and data are shared publicly (so as to facilitate research reproducibility) on the GitHub repository and this would allow others to build upon the project.
I’ve also created a video where I demonstrated in a step-by-step manner on how you can create your own data science portfolio on GitHub.
Aside from having a GitHub profile to share your data science projects, a portfolio website can be thought of as a digital name card that you can use for your personal branding. The portfolio website would of course include information on projects but it may also provide additional information that you wish to share (e.g. Educational backgrounds, Work experience, etc.).
Cover image created (with license) using the image by alexacrib from envato elements.